Concurrency with Go
This post will explore the distinctions between concurrency and parallelism in programming, focusing on how Go manages concurrency
According to wikipedia : In computer science, concurrency is the ability of different parts or units of a program, algorithm, or problem to be executed out-of-order or in partial order, without affecting the final outcome….. It further states that this allows parallel execution of concurrent unit; well that’s a lot to unpack if you ask me.
Concurrency is a very broad topic in computer science and in programming generally and a lot of smart people have put in the work over the years to make whatever abstractions we have today possible. Depending on who you ask and in what context, you may get different definitions of what it truly is but usually it is used to describe one or two things happening without one waiting for the other, that maybe true but not entirely because it oversimplifies concurrency to the point that it becomes hard to differentiate it from another similar concept called Parallelism.
Concurrency is an attribute of code structure while Parallelism is an attribute of code execution, this means that a concurrent program can be ran in parallel or not and still work fine. It’s also worth noting that parallelism is bound by operating system constraints such as how many cores are available and how many threads can be assigned to each core.
Illusion of Parallelism
The key difference between concurrency and parallelism is co-ordination of execution, while we can have two processes running simultaneously on different cores to achieve parallelism, concurrency does things different by running several coroutines on os threads and coordinating their execution to ensure there are no deadlocks.
At the core of go concurrency is the scheduler, it is the central coordinating unit responsible for creating go routines and pausing or resuming them when necessary.
Go routines and the Go Scheduler
Go routines are not os threads, they are in fact coroutines with special properties. We can create them by prepending the go keyword to any function call.
go ourFunc()
By default, the go scheduler creates a single goroutine for us when ever we run a go program; the main go routine without needing to specify the go keyword, any other go routines created by us will branch off this one and rejoin later at some point after execution. To get glimpse of what happens when these goroutines are created, let me introduce some important characters:
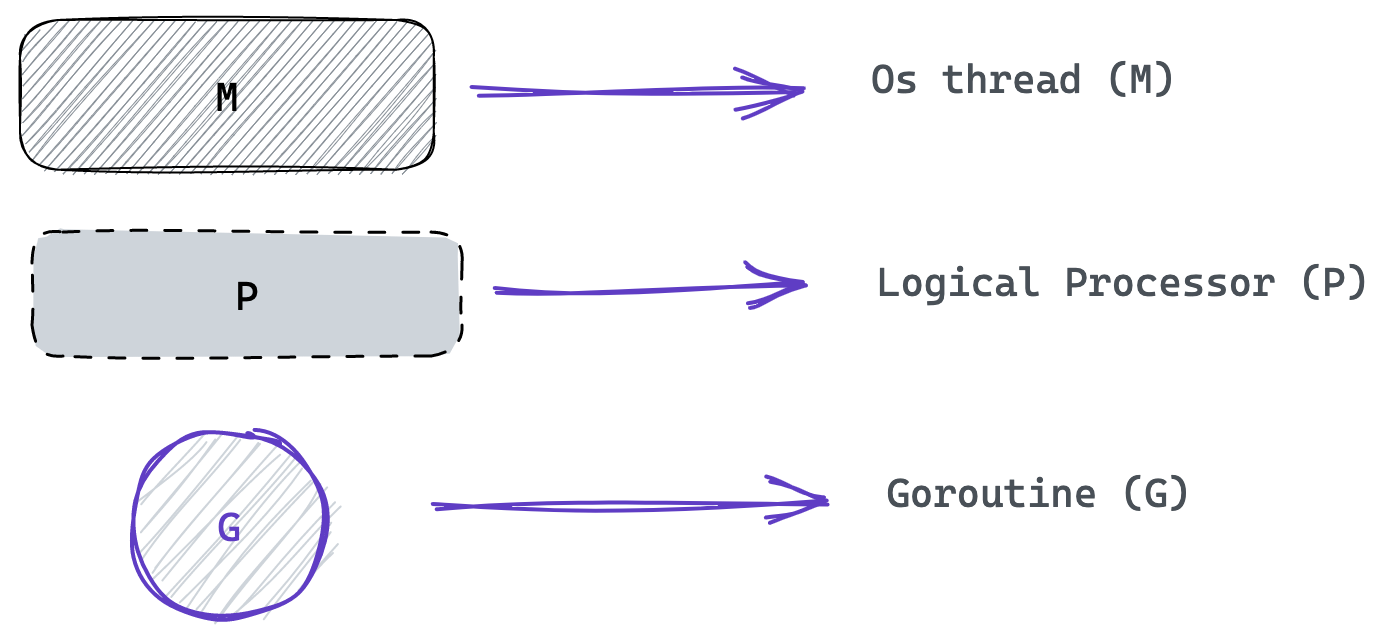
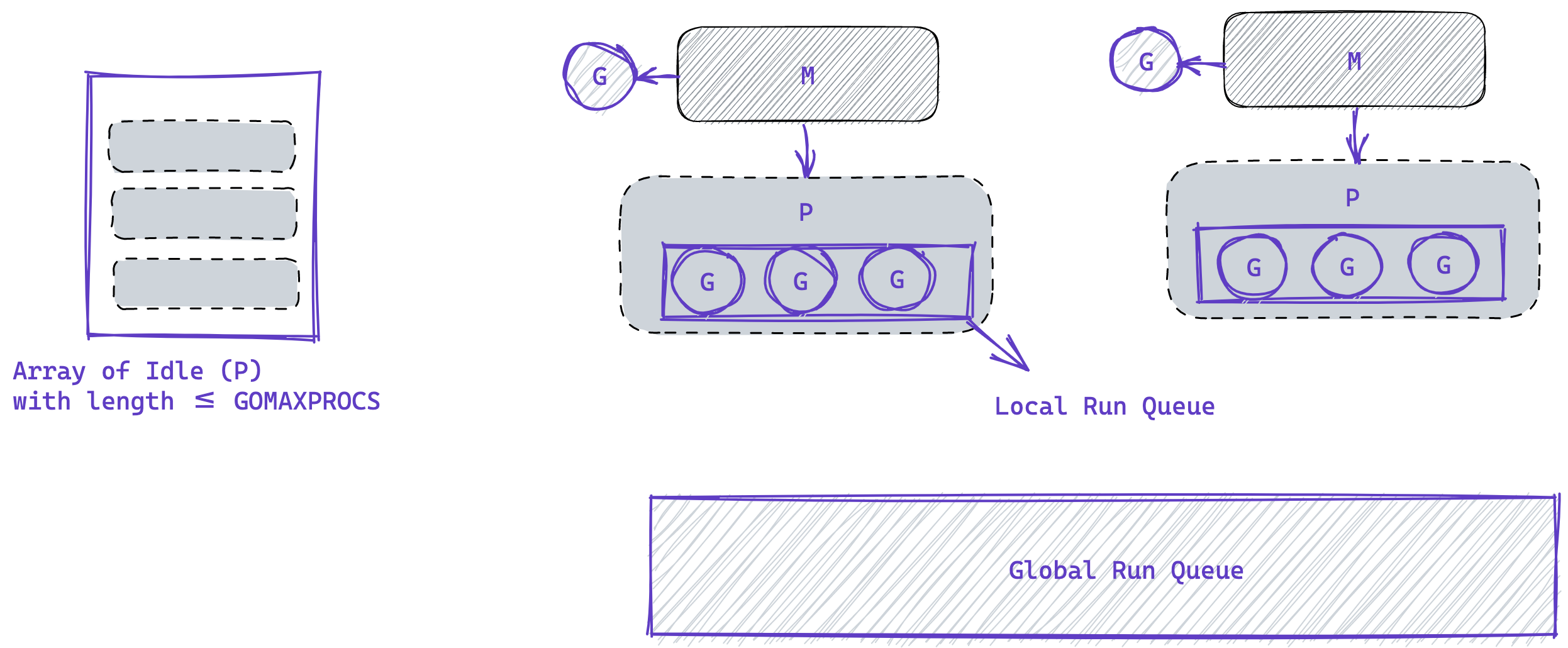
Go routines do not have a 1:1 relationship with os threads, instead the go scheduler uses an M:N approach where an arbitrary number of goroutines are assigned to an arbitrary number of os threads, this is made possible by the logical processors which are basically execution contexts, more like local copies of the go scheduler.
The job of the logical processor (P) is to keep track of and execute go routines (G), making sure that no goroutine is starved of resources, the number of logical processors and maximum OS threads can be tweaked by either setting the GOMAXPROCS environment variable or calling runtime.GOMAXPROCS with a value greater than zero.
The logical processors (P) start out in an array, and when ever a thread (M) needs to execute a goroutine (G), it pops off one idle (P) from the array and returns it when it is no longer needed. It keeps track of goroutines in a local queue, (M) regularly reaches out to the global run queue to fill up the local run queue in P, it also does this when P queue is empty.
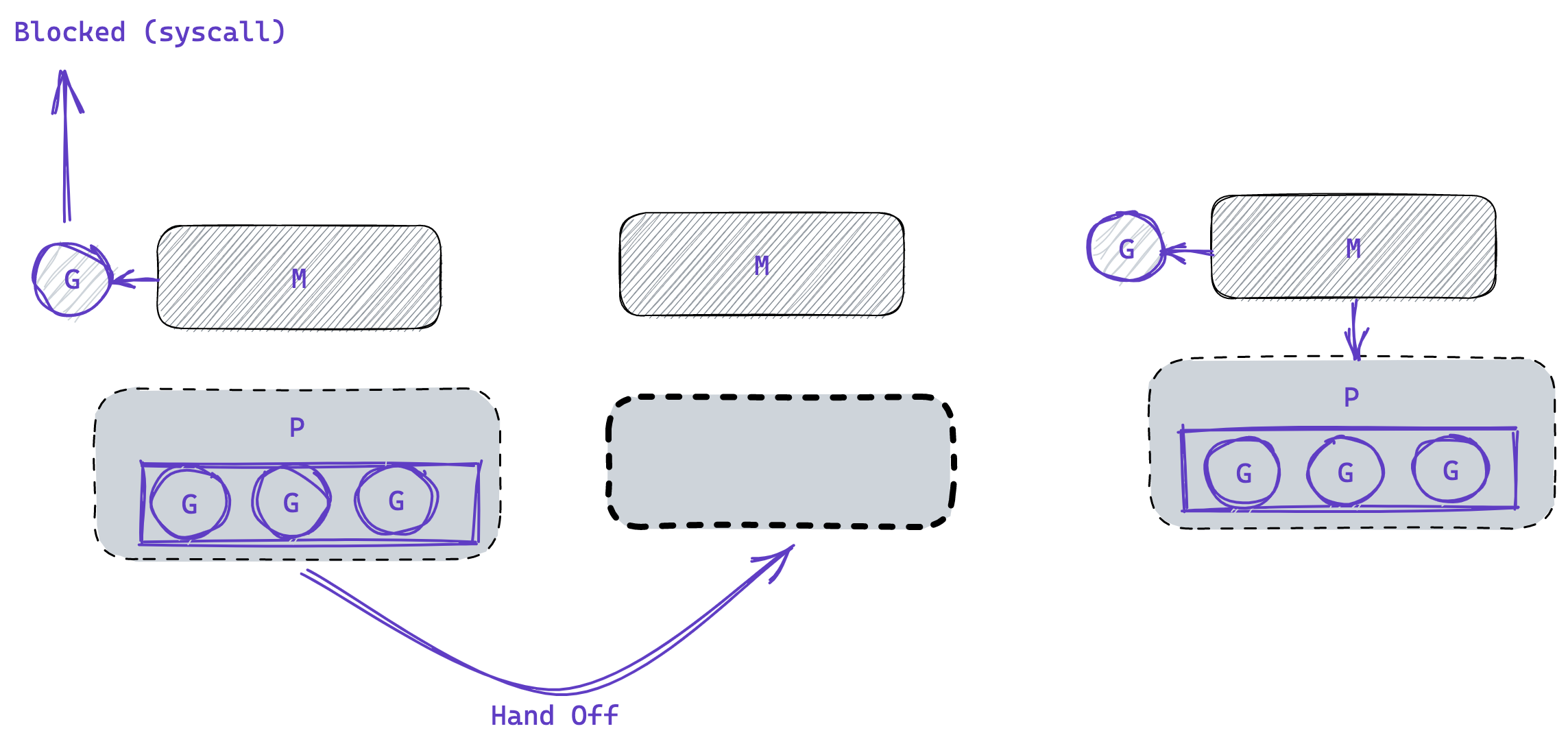
Go routines have three states; RUNNING, RUNNABLE and BLOCKED, there are several conditions that makes a goroutine BLOCKED, such as system or network call or just waiting for data to be returned from a channel, in the case where the goroutine becomes blocked, the thread (M) must handoff its (P) to another (M) and when it’s done it will attempt steal another (P) or push the goroutine (G) into the global run queue and go to sleep.
Memory Access Synchronisation
Go supports two models of concurrency; shared memory access and communicating sequential process (CSP), but it is generally advisable and idiomatic to use the later - CSP, however it is important to know what is possible and be able to decide the best which is better for the task at hand.
Shared memory access is implemented using mutex locks, which are used to synchronize access to shared variables between multiple concurrent goroutines. A mutex lock is a type of mutual exclusion mechanism that allows only one goroutine to access a shared resource at a time.
One issue that can arise when using mutex locks is the possibility of deadlock, where two or more goroutines are waiting for each other to release a mutex lock, resulting in a standstill.
To implement shared memory access with mutex locks in Go, you can use the sync.Mutex type provided by the Go standard library. This type provides the Lock and Unlock methods which can be used to acquire and release the mutex lock respectively.
For example the snippet demostrates a score variable being incremented by go routines which are spun in a loop without the use of locks.
type Counter struct {
score int
}
func (c *Counter) Inc() {
c.score += 10
}
func (c *Counter) Value() int {
return c.score
}
func main() {
c := Counter{}
for i := 0; i < 10; i++ {
go c.Inc()
}
time.Sleep(time.Second)
fmt.Println(c.Value())
}
Running the example with the go race detector flag in the terminal prints out a warning of possible data race.
go run -race main.go
==================
WARNING: DATA RACE
Read at 0x00c000136010 by goroutine 9:
main.(*Counter).Inc()
Same programme with mutex.Lock :
type Counter struct {
score int
mu sync.Mutex
}
func (c *Counter) Inc() {
c.mu.Lock()
c.score += 10
c.mu.Unlock()
}
func (c *Counter) Value() int {
c.mu.Lock()
defer c.mu.Unlock()
return c.score
}
func main() {
c := Counter{}
for i := 0; i < 10; i++ {
go c.Inc()
}
time.Sleep(time.Second)
fmt.Println(c.Value())
}
When ran with the -race flag:
go run -race main.go
100
Communicating Sequential Processes
CSP is a model of concurrency that was first introduced by computer scientist Tony Hoare in 1978. In CSP, concurrent processes communicate with each other by sending and receiving messages over channels, each process runs concurrently and is executed in isolation from the others. Any shared resource is accessed through a channel which ensures that only a single routine can access the resource at a time.
Channels are created using the make function and values are sent and received using the <- operator.
Some rules of channels
-
Trying to receive from a nil channel will result in deadlock
-
Trying to send to a nil channel will result in deadlock
-
Only the sending go routine should close the channel when all sending is done
-
Receiving from a closed channel will return the zero value for the channel type
-
Create channels with
make// 1. create with var keyword var myChan chan int // 2. create and initialise with make function myChan := make(chan int)While number (1) is valid go, it would result in a deadlock because
varinitialises the channel withnilwhere asmake()initialises it as an empty buffer. -
Sending on an unbuffered channel will be blocked until the previously sent value is read
package main import ( "fmt" ) func main() { myChan := make(chan int) go func() { for i := 0; i < 10; i++ { myChan <- i fmt.Printf("sent %d\n", i) } close(myChan) }() fmt.Printf("received %d\n", <-myChan) }Running it produces :
sent 0 received 0On the other hand, a buffered channel will accept values up to the capacity (+1) of the channel.
package main import ( "fmt" "time" ) func main() { // create a buffered channel with capacity of 4 myChan := make(chan int, 4) go func() { for i := 0; i < 5; i++ { myChan <- i fmt.Printf("sent %d\n", i) } close(myChan) }() fmt.Printf("received %d\n", <-myChan) time.Sleep(time.Second) }Running it produces:
sent 0 sent 1 sent 2 sent 3 sent 4 received 0
Lets say in our ealier counter example, we want to increment scores every 5 milliseconds and print them every 10 milliseconds.
type Counter struct {
scores map[int]int
}
type Score struct {
id int
score int
}
type ScoreReq struct {
response chan []Score
}
func main() {
update := make(chan ScoreReq)
scoreChan := make(chan Score)
// generate random scores and id and send them to scoreChan every 1ms
for i := 0; i < 100; i++ {
go func() {
id := rand.Intn(3)
score := rand.Intn(100)
time.Sleep(5 * time.Millisecond)
scoreChan <- Score{id, score}
}()
}
// update the counter with the scores from scoreChan
// and send the scores to the update channel if requested
go func() {
counter := Counter{make(map[int]int)}
for {
select {
case req := <-update:
scores := make([]Score, 0)
for id, score := range counter.scores {
scores = append(scores, Score{id, score})
}
req.response <- scores
case score := <-scoreChan:
counter.scores[score.id] += score.score
}
}
}()
// request the scores from the update channel every 1ms and print them
go func() {
for {
req := ScoreReq{make(chan []Score)}
update <- req
scores := <-req.response
for _, score := range scores {
fmt.Printf("\tid: %d, score: %d\n", score.id, score.score)
}
fmt.Println("-----------")
time.Sleep(10 * time.Millisecond)
}
}()
time.Sleep(time.Second)
}
Without the use of mutexes, several go routines are writing and reading from the counter struct owned by one go routine. The scoreChan receives new scores from one go routine while the update chan serves as a pipe between the printing routine and the one that owns the counter struct.
Do not communicate by sharing memory; instead, share memory by communicating.Common patterns and Error handling
These are patterns that are most reoccurring when writing concurrent code, they are not necessarily design patterns. For a detailed example on concurrency patterns check out :go concurrency patterns.
Receiving from a Channel:
func main() {
myChan := make(chan int)
go func() {
for i := 0; i < 5; i++ {
myChan <- i
fmt.Printf("sent %d\n", i)
}
close(myChan)
}()
for i := range myChan {
fmt.Printf("received %d\n", i)
}
}
Receiving from multiple Channels:
To receive from two or more channels, go provides the select statement which works like your regular switch statement
func main() {
blueChan := make(chan string)
redChan := make(chan string)
go func() {
for i := 0; i < 10; i++ {
blueChan <- "blue"
}
}()
go func() {
for i := 0; i < 10; i++ {
redChan <- "red"
}
}()
for i := 0; i < 10; i++ {
select {
case msg := <-blueChan:
fmt.Println(msg)
case msg := <-redChan:
fmt.Println(msg)
default:
fmt.Println("default executed")
}
}
}
Wait for go routines to exit:
The sync package provides a struct - WaitGroup which lets us wait for goroutines by incrementing and decrementing a counter, Add increments the counter, Done decrements it by 1 and Wait blocks until the counter is 0.
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
for i := 0; i < 10; i++ {
// fmt.Println("Hello")
}
defer wg.Done()
}()
go func() {
defer wg.Done()
for i := 0; i < 10; i++ {
// fmt.Println("World")
}
}()
wg.Wait()
fmt.Println("All routines done")
}
Time out:
func main() {
hChan := make(chan string)
wChan := make(chan string)
go func() {
for i := 0; i < 10; i++ {
hChan <- "hello"
time.Sleep(1 * time.Second)
}
}()
go func() {
for i := 0; i < 10; i++ {
wChan <- "world"
time.Sleep(1 * time.Second)
}
}()
for {
select {
case h := <-hChan:
fmt.Println(h)
case w := <-wChan:
fmt.Println(w)
case <-time.After(1 * time.Second):
fmt.Println("timeout, exiting ...")
return
}
}
}
Closing Note
While it may be tempting to throw in concurrency at every problem you encounter, know that concurrency doesn’t always guarantee faster execution and not using them properly could lead to issues such as memory leaks.